Hier eine Liste der von mir entwickelten Tools.
Word Embeddings
Hier geht es zum Analogierechner:
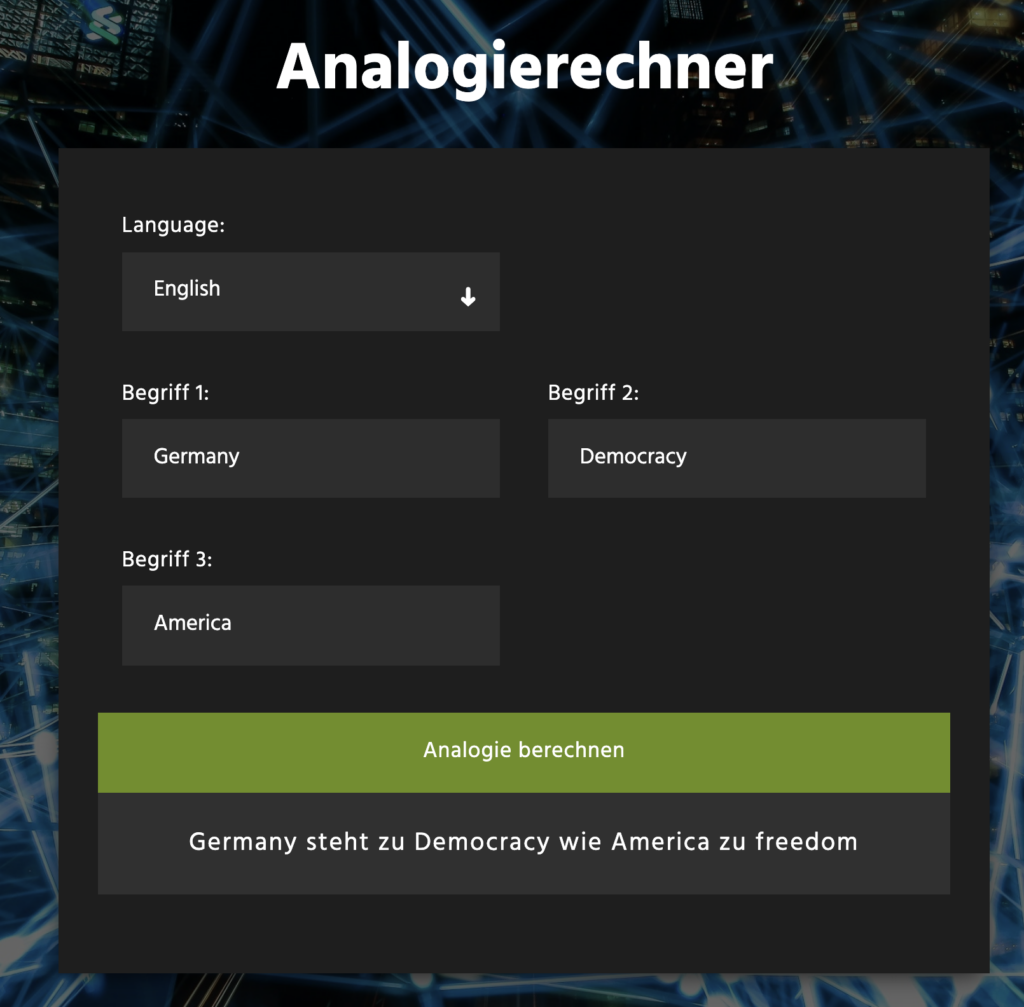
In zwei Sprachen (Englisch und Deutsch) können hier sprachliche Analogien berechnet werden. Technologische Grundlage hierfür bilden Word Embeddings. Mithilfe mathematischer Algorithmen wird anhand riesiger Textcorpora (beispielsweise: Wikipedia) eine Einbettung von Worten in einen hochdimensionalen Raum erlernt, bei dem die Vektoren der Abstände sich semantisch interpretieren lassen. Hier lassen sich nicht nur die Klassiker der Semantischen Relationen nachvollziehen („König steht zu Königin wir Prinz zu Prinzessin“), sondern auch selbst mit Analogien rumspielen.
Nette Ergebnisse sind zum Beispiel:
- „Rice steht zu China wie Bacon zu Germany“
- „Democracy steht zu Deutschland wie Freedom zu America“
- „Mann steht zu Sex wie Frau zu Freundin“
Probiert es aus 😉
Genutzte Algorithmen und Technologien: Word Embeddings, Pyton, plotly, dash, flask, HTML, CSS, AWS EC2, AWS Elastic Block Store
Verworfene Ansätze und Technologien: nltk, gensim, heroku, git lfs, AWS S3, AWS CodePipeline, AWS Elastic Beanstalk
Bundestagsmining
Hier geht es zum Bundestag Dashboard:
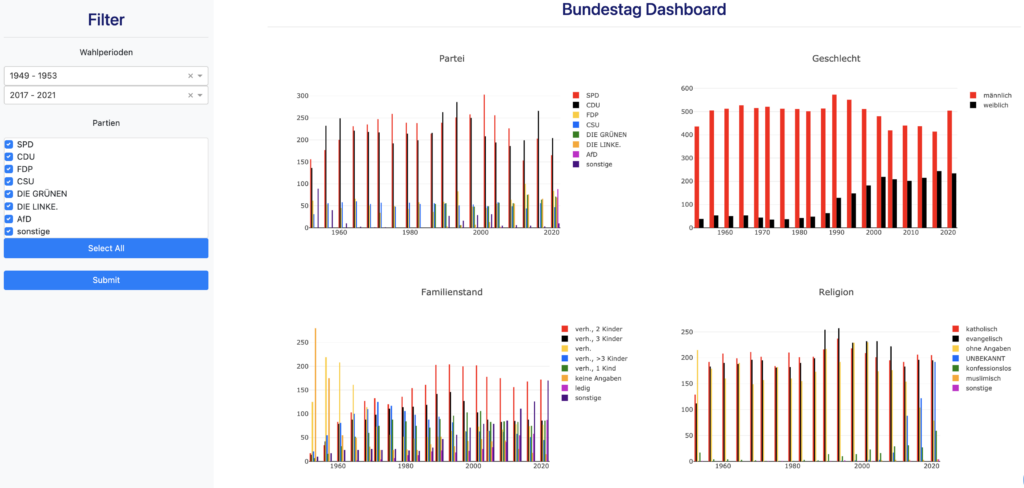
Was sind das eigentlich für Menschen, die uns im Bundestag vertreten? Wie alt sind sie, was waren sie vorher von Beruf, wie sind Religionszugehörigkeit oder dem Familienstatus unter den Bundestagsabgeordneten verteilt? Wer diese und noch mehr Fragen systematisch auswerten möchte, kann gerne das interaktive Bundestagsdashboard dazu nutzen.
Genutzte Algorithmen und Technologien: Python, re, plotly, dash, flask, XML, Docker, AWS Elastic Container Registry, AWS Elastic Container Service
Hi, was ist denn die Quelle des Datensatzes fürs Bundestagsdashboard? Würde damit selbst gerne ein wenig herumspielen.
Hi Quentin, die Daten findest Du auf https://www.bundestag.de/services/opendata unter „Stammdaten aller Abgeordneten seit 1949 im XML-Format“. Viel Spaß! 😉