In Teil 3 des BundestagsMining Projektes haben wir uns mithilfe des Bundestags-Report-Generators mit der Verteilung von Religion und Familienstand der Bundestagsabgeordneten beschäftigt. Folgende Beobachtungen konnten wir dabei machen:
- Die Abgeordneten sind ganz überwiegend christlich. Es gibt zwar einen steigenden Anteil an konfessionslosen. Aber während die Konfessionslosen in der BRD mit 39 Prozent den größten Anteil ausmachen, sind es im Bundestag mit 59 von 467, die dazu eine Angabe gemacht haben, gerade mal 13%.
- Noch extremer ist die Situation bezüglich des muslimischen Glaubens, die ca 7% der Gesamtbevölkerung ausmachen, während sie im Bundestag gerade mal mit knapp einem Prozent vertreten sind (4 von 467, gemäß der Angaben in unserer Hauptquelle).
- Auch hier gibt es starke Unterschiede zwischen den Parteien; erwartungsgemäß haben die Vertreter der CSU mit 74 Prozent einen sehr dominanten katholischen Anteil, während bei den Linken die konfessionslosen überwiegen. Die SPD ist evangelischer als die CDU usw. Nutzt einfach das Bundestags Dashboard, um euch die Zahlen anzugucken, die euch interessieren
- Ähnlich eintönig wie die Religionsverteilung ist auch die der familiären Konstellationen: die allermeisten Abgeordneten sind verheiratet und haben 1 bis 3 Kinder. Dabei homogenisiert sich die Verteilung zunehmend in Richtung des „Standardmodells“ mit 2 Kindern. Gerade mal 16% (87 von 559 Abgeordneten, die eine Angabe zu dem Punkt machten) sind ledig, während der Anteil in der Gesamtbevölkerung mehr als doppelt so hoch ist.
Kommen wir nun zum letzten und für diese Untersuchung ja eigentlich ausschlaggebenden Feld: wie sieht es nun aus mit der beruflichen Diversität? stimmt die „gefühlte Wahrheit“, dass fast alle Abgeordneten Juristen und BWLer sind, oder ist das nur ein Trugschluss, weil eher zufällig viele der bekannten Minister aus diesen Bereichen kommen? Ist der Bundestag vielleicht sogar besser als sein Ruf und keine Bubble aus Akademikern und Büroangestellten sondern ein echtes Abbild der Gesellschaft mit all seinen verschiedenen Berufsgruppen und Milieus?
Detailfrage 8: Wie divers ist der Bundestag bezüglich der beruflichen Hintergründe der Abgeordneten?
Sehen wir uns die Häufigkeit aller Berufsangaben in den Originaldaten an, ergibt sich folgendes Bild:
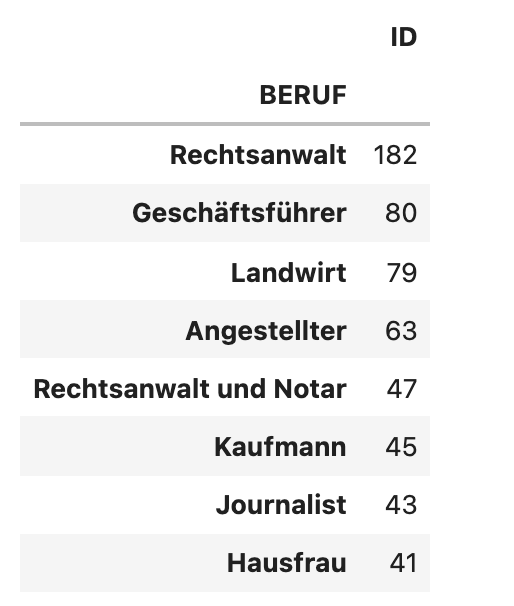
Einerseits bestätigt das halbwegs das Vorurteil (Rechtsanwälte scheinen stark überrepräsentiert zu sein) andererseits ist diese Tabelle so noch gar nicht besonders aussagekräftig; bei über 4000 Abgeordneten ergeben sich nämlich 2201 verschiedene Berufsbezeichnungen, deren Verteilung sich schwer auf einen Blick erfassen lässt.
Das liegt einerseits daran, dass natürlich allgemeine Berufsgruppen unter verschiedenen konkreten Bezeichnungen auftauchen („Rechtsanwalt“ vs. „Jurist“) und andererseits an dem Phänomen, dass viele sehr komplexen und daher einmaligen Berufsbezeichnung aufgelistet sind. So ist bei Annette Schavan ganz sparsam als Beruf folgendes angegeben: „MdL a. D., Ministerin für Kultus, Jugend und Sport a. D., Bundesministerin für Bildung und Forschung a. D.“ und der SPD Abgeordnete Burkhard Lischka ist „Notar, Sprecher für Recht und Verbraucherschutz, Obmann im Parlamentarischen Kontrollgremium, Staatssekretär a. D.“ Mit diesem Beruf ist er denn auch der einzige.
Kurz: um die Verteilung der Berufe sinnvoll auszuwerten, muss ein gutes Mapping her, das spezielle Bezeichnungen (z.B. „Grundschullehrer“, „Hauptschullehrer'“, „Gynmasiallehrer“) zu einer allgemeinen Berufsgruppe (z.B. „Lehrer“) zuordnet. Als guter Data Scientist habe ich lange versucht, auch diese Aufgabe zu automatisieren, indem ich die Berufe in Wordembeddings gesucht und ein Mapping über ein Clustering im niedrigdimensionalen Einbettungsraum versucht habe. Die Cluster der Berufe, die im Embedding (hier: ein vortrainiertes Deutsches GloVe Modell) gefunden wurden, waren per se erfreulich sinnvoll:

Dennoch blieb das riesige Problem von unmappbaren, weil überindividualisierten Berufsbezeichnungen (siehe das Beispiel von Annette Schavan).
Sehr schöne Abendlektüre, vielen Dank dafür!
Das ist die Mischung, die mein Data Science Herz aufgehen lässt:
– wie die Analysen immer aufwendiger werden, weil noch kurz Word Embeddings, ein Dashboard oder Regexe eingebaut werden sollen
– wie der Perfektionismus durchkommt und immer noch erklärt wird, dass ja alles nicht sauber ist und was man alles noch zusätzlich machen könnte
– wie gleichzeitig aber doch ganz viele verschiedene Themen integriert werden, in diesem Fall gesellschaftlicher Natur (gendergerechte Berufe, Anteil an Single-Haushalten oder oder oder)
– und am Schluss irgendwie der rote Faden noch da ist und die Handlungsempfehlungen rüberkommen
Und ja, ich hätte 1000e Ideen, wo man nochmal reinschauen könnte. Beispielsweise nimmt der Anteil der Personen in Erwerbstätigkeit in der Landwirtschaft nun auch in der Gesamtbevölkerung ab (https://de.statista.com/statistik/daten/studie/242856/umfrage/bedeutung-der-landwirtschaft-nach-anzahl-der-erwerbstaetigen/), was aber sicherlich nicht gegen die These spricht, dass keine repräsentative Vertretung vorhanden ist. Und warum dürfen Politiker nach einer Scheidung nicht wieder verheiratet sein? Und wollen wir überhaupt lieber ältere PolitikerInnen, weil sie mehr Erfahrung haben, oder lieber jüngere und ledige NaturwissenschaftlerInnen, die anders denken? Vielleicht checke ich doch lieber nochmal die wahl-o-mat Analyse von David Kriesel, da gibt es zumindest nur endliche Optionen 😉
Und ja: Warum gibt es eigentlich kein Python-Paket, das gendern kann? Gibt es nicht schon genug Texte, bei denen man die Wortneuschöpfungen rausziehen könnte? Mit *chen, Innen oder sonstwas? Mal auf die endlose Liste guter Ideen setzen, vielleicht kommt ja mal so richtig schlechtes Wetter …
Aber auch aus technisch-finanziellem Interesse: Warum kostet dein Dashboard nur in ECR und nichts in ECS? Gibt es da keine Run Costs? Das Dashboard ist ja immerhin öffentlich erreichbar und nutzbar und der Container läuft doch bestimmt auch dauerhaft.
Zum Schluss, completely unrelated, warum fehlt im Seitentitel und Footer das R? Das triggert mich 😉
Also Danke nochmal, war schön zu lesen.